Abstract
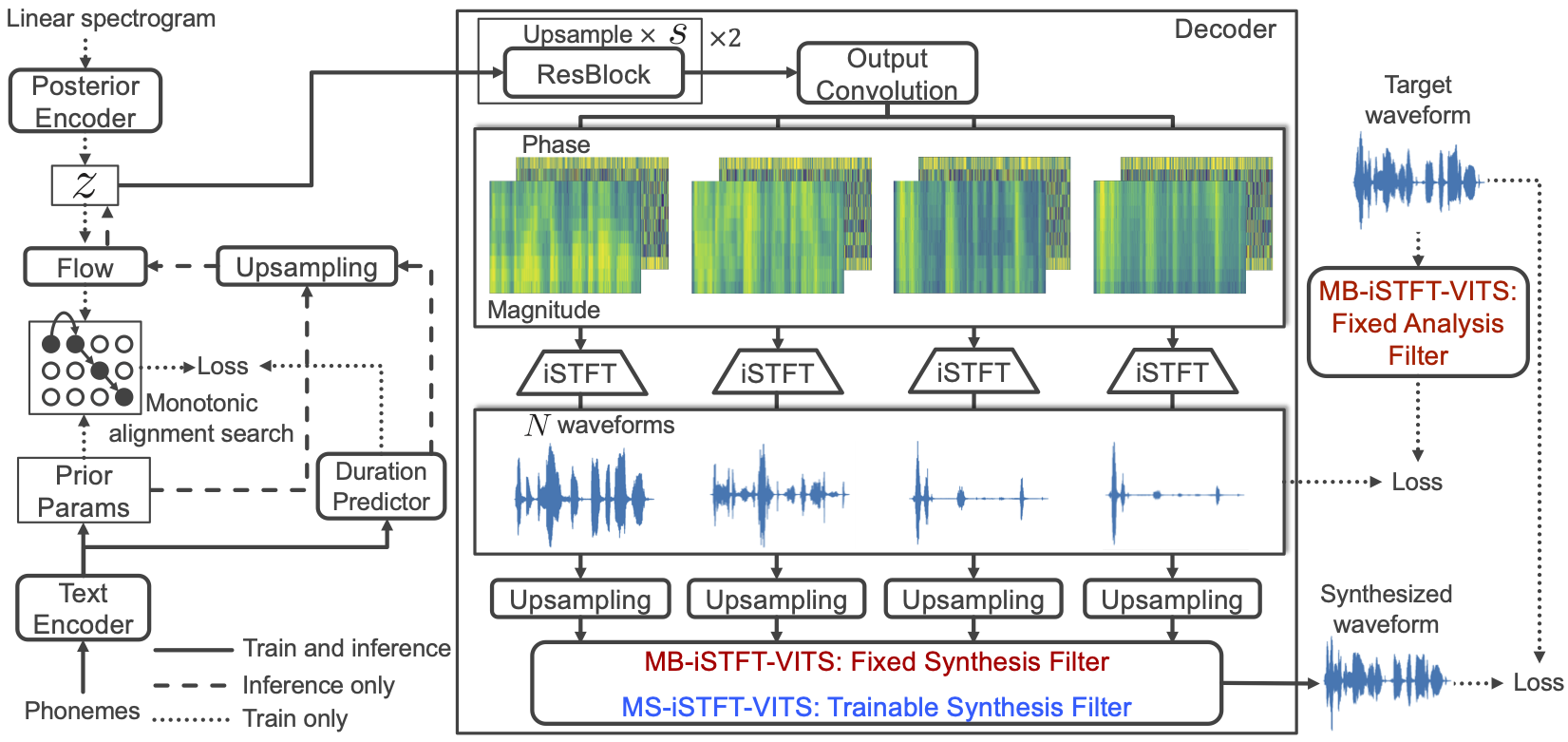
We propose a lightweight end-to-end text-to-speech model using multi-band generation and inverse short-time Fourier transform. Our model is based on VITS, a high-quality end-to-end text-to-speech model, but adopts two changes for more efficient inference: 1) the most computationally expensive component is partially replaced with a simple inverse short-time Fourier transform, and 2) multi-band generation, with fixed or trainable synthesis filters, is used to generate waveforms. Unlike conventional lightweight models, which employ optimization or knowledge distillation separately to train two cascaded components, our method enjoys the full benefits of end-to-end optimization. Experimental results show that our model synthesized speech as natural as that synthesized by VITS, while achieving a real-time factor of 0.066 on an Intel Core i7 CPU, 4.1 times faster than VITS. Moreover, a smaller version of the model significantly outperformed a lightweight baseline model with respect to both naturalness and inference speed. Code and audio samples are available from https://github.com/MasayaKawamura/MB-iSTFT-VITS.
Demo
This is an accompanying page and includes some examples of the synthesized speech obtained with the proposed and conventional methods. The groundtruth audio clips are from the LJ speech dataset [1]. These clips are not included in the training data.